|
|
COM Collection and Enumeration InterfacesStandard C++ Containers and IteratorsC++ programmers long ago learned to separate their collections into three pieces: the data itself, the container of the data, and an iterator for accessing the data. This separation is useful for building pieces separately from each other. The container's job is to enable the user to affect the contents of the collection. The iterator's job is to enable the user to access the contents of the container. And although the iterator implementation depends on how the container stores the data, the implementation details are hidden from the client of the container and the iterator. For example, imagine the following code for populating a container and then accessing it via an iterator:
void main() {
// Populate the collection
vector<long> rgPrimes;
for (long n = 0; n != 1000; ++n) {
if (IsPrime(n)) rgPrimes.push_back(n);
}
// Count the number of items in the collection
cout << "Primes: " << rgPrimes.size() << endl;
// Iterate over the collection using sequential access
vector<long>::iterator begin = rgPrimes.begin();
vector<long>::iterator end = rgPrimes.end();
for (vector<long>::iterator it = begin; it != end; ++it) {
cout << *it << " ";
}
cout << endl;
}
Because the container provides a well-known C++ interface, the client does not need to know the implementation details. In fact, C++ container classes are so uniform that this simple example would work just as well with a list or a deque as it does with a vector. Likewise, because the iterators that the container provides are uniform, the client doesn't need to know the implementation details of the iterator. For the client to enjoy these benefits, the container and the iterator have certain responsibilities. The responsibilities of the container include the following:
Likewise, the responsibilities of the iterator entail the following:
Although C++ containers and iterators are handy in your C++ code, neither is useful as a way of communicating data via a COM interface. Instead, we turn to the COM equivalent of containers and iterators: COM collections and enumerators. COM Collections and EnumeratorsA COM collection is a COM object that holds a set of data and allows the client to manipulate its contents via a COM interface. In many ways, a COM collection is similar to a C++ container. Unfortunately, IDL doesn't support templates, so it's impossible to define a generic ICollection interface. Instead, COM defines collections through coding conventions. By convention, a COM collection interface takes a minimum form. This form is shown here, pretending that IDL supported templates: [ object, dual ] template <typename T> interface ICollection : IDispatch { [propget] HRESULT Count([out, retval] long* pnCount); [id(DISPID_VALUE), propget] HRESULT Item([in] long n, [out, retval] T* pnItem); [id(DISPID_NEWENUM), propget] HRESULT _NewEnum([out, retval] IUnknown** ppEnum); }; Several features about this interface are worth noting:
None of the methods specified earlier is actually required; you need to add only the methods you expect to support. However, it's highly recommended to have all three. Without them, you've got a container with inaccessible contents, and you can't even tell how many things are trapped in there. A COM enumerator is to a COM collection as an iterator is to a container. The collection holds the data and allows the client to manipulate it, and the enumerator allows the client sequential access. However, instead of providing sequential access one element at a time, as with an iterator, an enumerator allows the client to decide how many elements it wants. This enables the client to balance the cost of round-trips with the memory requirements to handle more elements at once. A COM enumerator interface takes the following form (again, pretending that IDL supported templates): template <typename T> interface IEnum : IUnknown { [local] HRESULT Next([in] ULONG celt, [out] T* rgelt, [out] ULONG *pceltFetched); [call_as(Next)] // Discussed later... HRESULT RemoteNext([in] ULONG celt, [out, size_is(celt), length_is(*pceltFetched)] T* rgelt, [out] ULONG *pceltFetched); HRESULT Skip([in] ULONG celt); HRESULT Reset(); HRESULT Clone([out] IEnum<T> **ppenum); } A COM enumerator interface has the following properties:
Custom Collection and Enumerator ExampleFor example, let's model a collection of prime numbers as a COM collection:
[dual]
interface IPrimeNumbers : IDispatch {
HRESULT CalcPrimes([in] long min, [in] long max);
[propget]
HRESULT Count([out, retval] long* pnCount);
[propget, id(DISPID_VALUE)]
HRESULT Item([in] long n, [out, retval] long* pnPrime);
[propget, id(DISPID_NEWENUM)] // Not quite right...
HRESULT _NewEnum([out, retval] IEnumPrimes** ppEnumPrimes);
};
The corresponding enumerator looks like this:
interface IEnumPrimes : IUnknown {
[local]
HRESULT Next([in] ULONG celt,
[out] long* rgelt,
[out] ULONG *pceltFetched);
[call_as(Next)]
HRESULT RemoteNext([in] ULONG celt,
[out, size_is(celt),
length_is(*pceltFetched)] long* rgelt,
[out] ULONG *pceltFetched);
HRESULT Skip([in] ULONG celt);
HRESULT Reset();
HRESULT Clone([out] IEnumPrimes **ppenum);
};
Porting the previous C++ client to use the collection and enumerator looks like this:
void main() {
CoInitialize(0);
CComPtr<IPrimeNumbers> spPrimes;
if (SUCCEEDED(spPrimes.CoCreateInstance(CLSID_PrimeNumbers))) {
// Populate the collection
HRESULT hr = spPrimes->CalcPrimes(0, 1000);
// Count the number of items in the collection
long nPrimes;
hr = spPrimes->get_Count(&nPrimes);
cout << "Primes: " << nPrimes << endl;
// Enumerate over the collection using sequential access
CComPtr<IEnumPrimes> spEnum;
hr = spPrimes->get__NewEnum(&spEnum);
const size_t PRIMES_CHUNK = 64;
long rgnPrimes[PRIMES_CHUNK];
do {
ULONG celtFetched;
hr = spEnum->Next(PRIMES_CHUNK, rgnPrimes, &celtFetched);
if (SUCCEEDED(hr)) {
if (hr == S_OK) celtFetched = PRIMES_CHUNK;
for (long* pn = &rgnPrimes[0];
pn != &rgnPrimes[celtFetched]; ++pn) {
cout << *pn << " ";
}
}
}
while (hr == S_OK);
cout << endl;
spPrimes.Release();
}
CoUninitialize();
}
This client code asks the collection object to populate itself via the CalcPrimes method instead of adding each prime number one at a time. Of course, this procedure reduces round-trips. The client further reduces round-trips when retrieving the data in chunks of 64 elements. A chunk size of any number greater than 1 reduces round-trips but increases the data requirement of the client. Only profiling can tell you the right number for each client/enumerator pair, but larger numbers are preferred to reduce round-trips. Dealing with the Enumerator local/call_as OddityOne thing that's rather odd about the client side of enumeration is the pceltFetched parameter filled by the Next method. The COM documentation is ambiguous, but it boils down to this: When only a single element is requested, the client doesn't have to provide storage for the number of elements fetchedthat is, pceltFetched is allowed to be NULL. Normally, however, MIDL doesn't allow an [out] parameter to be NULL. So, to support the documented behavior for enumeration interfaces, all of them are defined with two versions of the Next method. The [local] Next method is for use by the client and allows the pceltFetched parameter to be NULL. The [call_as] RemoteNext method doesn't allow the pceltFetched parameter to be NULL and is the method that performs the marshaling. Although the MIDL compiler implements the RemoteNext method, we have to implement Next manually because we've marked the Next method as [local]. In fact, we're responsible for implementing two versions of the Next method. One version is called by the client and, in turn, calls the RemoteNext method implemented by the proxy. The other version is called by the stub and calls the Next method implemented by the object. Figure 8.1 shows the progression of calls from client to object through the proxy, the stub, and our custom code. The canonical implementation is as follows: static HRESULT STDMETHODCALLTYPE IEnumPrimes_Next_Proxy( IEnumPrimes* This, ULONG celt, long* rgelt, ULONG* pceltFetched) { ULONG cFetched; if (!pceltFetched && celt != 1) return E_INVALIDARG; return IEnumPrimes_RemoteNext_Proxy(This, celt, rgelt, pceltFetched ? pceltFetched : &cFetched); } static HRESULT STDMETHODCALLTYPE IEnumPrimes_Next_Stub( IEnumPrimes* This, ULONG celt, long* rgelt, ULONG* pceltFetched) { HRESULT hr = This->lpVtbl->Next(This, celt, rgelt, pceltFetched); if (hr == S_OK && celt == 1) *pceltFetched = 1; return hr; } Figure 8.1. Call progression from client, through proxy and stub, to implementation of IEnumPrimes
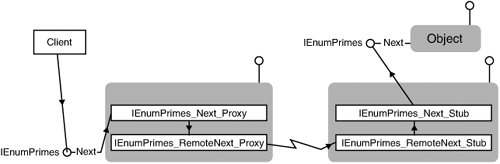
Every enumeration interface includes this code in the proxy/stub implementation, including all the standard ones, such as IEnumUnknown, IEnumString, and IEnumVARIANT. The only difference in implementation is the name of the interface and the type of data being enumerated over (as shown in the IEnumPrimes example in bold). When you're building the proxy/stub for your project using the <project>PS project generated by the ATL project template, and you have a custom enumeration interface, it's your job to inject that code into your proxy/stub. One way is to edit the <project>_p.c file, but if you were to recompile the IDL, the implementation would be lost. Another way is to add another .c file to the proxy/stub project. This is rather unpleasant and requires that you remember to update this code every time you edit the IDL file. The technique I prefer relies on macro definitions used during the proxy-/stub-building process and makes heavy use of the cpp_quote statement in IDL.[1] Whenever you have a custom enumeration interface, insert code like this at the bottom of the IDL file, and all will be right with the world (the bold code changes based on the enumeration interface):
cpp_quote("#ifdef __midl_proxy")
cpp_quote("static HRESULT STDMETHODCALLTYPE")
cpp_quote("IEnumPrimes_Next_Proxy")
cpp_quote("(IEnumPrimes* This, ULONG celt, long* rgelt,
ULONG* pceltFetched)")
cpp_quote("{")
cpp_quote(" ULONG cFetched;")
cpp_quote(" if( !pceltFetched && celt != 1 )
return E_INVALIDARG;")
cpp_quote(" return IEnumPrimes_RemoteNext_Proxy(This, celt,
rgelt,")
cpp_quote(" pceltFetched ?
pceltFetched : &cFetched);")
cpp_quote("}")
cpp_quote("")
cpp_quote("static HRESULT STDMETHODCALLTYPE")
cpp_quote("IEnumPrimes_Next_Stub")
cpp_quote("(IEnumPrimes* This, ULONG celt, long* rgelt,
ULONG* pceltFetched)")
cpp_quote("{")
cpp_quote(" HRESULT hr = This->lpVtbl->Next(This, celt, rgelt,")
cpp_quote(" pceltFetched);")
cpp_quote(" if( hr == S_OK && celt == 1 ) *pceltFetched = 1;")
cpp_quote(" return hr;")
cpp_quote("}")
cpp_quote("#endif // __midl_proxy")
All the code within the cpp_quote statements is deposited into the <project>.h file, but because the __midl_proxy symbol is used, the code is compiled only when building the proxy/stub. An Enumeration IteratorOne other niggling problem with COM enumerators is their ease of useor, rather, the lack thereof. It's good that a client has control of the number of elements to retrieve in a single round-trip, but logically the client is still processing the data one element at a time. This is obfuscated by the fact that we're using two loops instead of one. Of course, C++ being C++, there's no reason that a wrapper can't be built to remove this obfuscation.[2] Such a wrapper is included with the source code examples for this book. It's called the enum_iterator and is declared like this:
#ifndef ENUM_CHUNK
#define ENUM_CHUNK 64
#endif
template <typename EnumItf, const IID* pIIDEnumItf,
typename EnumType, typename CopyClass = _Copy<EnumType> >
class enum_iterator {
public:
enum_iterator(IUnknown* punkEnum = 0,
ULONG nChunk = ENUM_CHUNK);
enum_iterator(const enum_iterator& i);
~enum_iterator();
enum_iterator& operator=(const enum_iterator& rhs);
bool operator!=(const enum_iterator& rhs);
bool operator==(const enum_iterator& rhs);
enum_iterator& operator++();
enum_iterator operator++(int);
EnumType& operator*();
private:
...
};
The enum_iterator class provides a standard C++-like forward iterator that wraps a COM enumerator. The type of the enumeration interface and the type of data that it enumerates are specified as template parameters. The buffer size is passed, along with the pointer to the enumeration interface, as a constructor argument. The first constructor allows for the common use of forward iterators. Instead of asking a container for the beginning and ending iterators, the beginning iterator is created by passing a non-NULL enumeration interface pointer. The end iterator is created by passing NULL. The copy constructor is used when forming a looping statement. This iterator simplifies the client enumeration code considerably: ... // Enumerate over the collection using sequential access CComPtr<IEnumPrimes> spEnum; hr = spPrimes->get__NewEnum(&spEnum); // Using an C++-like forward iterator typedef enum_iterator<IEnumPrimes, &IID_IEnumPrimes, long> primes_iterator; primes_iterator begin(spEnum, 64); primes_iterator end; for (primes_iterator it = begin; it != end; ++it) { cout << *it << " "; } cout << endl; ... Or if you'd like to get a little more fancy, you can use the enum_iterator with a function object and a standard C++ algorithm, which helps you avoid writing the looping code altogether:
struct OutputPrime {
void operator()(const long& nPrime) {
cout << nPrime << " ";
}
};
...
// Using a standard C++ algorithm
typedef enum_iterator<IEnumPrimes, &IID_IEnumPrimes, long>
primes_iterator;
for_each(primes_iterator(spEnum, 64), primes_iterator(),
OutputPrime());
...
This example might not be as clear to you as the looping example, but it warms the cockles of my C++ heart. Enumeration and Visual Basic 6.0In the discussion that follows and in all references to Visual Basic in this chapter, we talk specifically about Visual Basic 6.0, not the latest version, VB .NET. COM collections and enumerations evolved with VB6 in mind, so it's insightful to examine client-side programming with VB6 and collections. VB .NET, of course, is an entirely different subject and squarely outside the scope of this book. The C++ for_each algorithm might seem a lot like the Visual Basic 6.0 (VB) For-Each statement, and it is. The For-Each statement allows a VB programmer to access each element in a collection, whether it's an intrinsic collection built into VB or a custom collection developed using COM. Just as the for_each algorithm is implemented using iterators, the For-Each syntax is implemented using a COM enumeratorspecifically, IEnumVARIANT. To support the For-Each syntax, the collection interface must be based on IDispatch and must have the _NewEnum property marked with the special DISPID value DISPID_NEWENUM. Because our prime number collection object exposes such a method, you might be tempted to write the following code to exercise the For-Each statement:
Private Sub Command1_Click()
Dim primes As IPrimeNumbers
Set primes = New PrimeNumbers
primes.CalcPrimes 0, 1000
MsgBox "Primes: " & primes.Count
Dim sPrimes As String
Dim prime As Variant
For Each prime In primes ' Calls Invoke(DISPID_NEWENUM)
sPrimes = sPrimes & prime & " "
Next prime
MsgBox sPrimes
End Sub
When VB sees the For-Each statement, it invokes the _NewEnum property, looking for an enumerator that implements IEnumVARIANT. To support this use, our prime number collection interface must change from exposing IEnumPrimes to exposing IEnumVARIANT. Here's the twist: The signature of the method is actually _NewEnum(IUnknown**), not _NewEnum(IEnumVARIANT**). VB takes the IUnknown* returned from _NewEnum and queries for IEnumVARIANT. It would've been nice for VB to avoid an extra round-trip, but perhaps at one point, the VB team expected to support other enumeration types. Modifying IPrimeNumbers to support the VB For-Each syntax looks like this: [dual] interface IPrimeNumbers : IDispatch { HRESULT CalcPrimes([in] long min, [in] long max); [propget] HRESULT Count([out, retval] long* pnCount); [propget, id(DISPID_VALUE)] HRESULT Item([in] long n, [out, retval] long* pnPrime); [propget, id(DISPID_NEWENUM)] HRESULT _NewEnum([out, retval] IUnknown** ppunkEnum); }; This brings the IPrimeNumbers interface into line with the ICollection template form we showed you earlier. In fact, it's fair to say that the ICollection template form was defined to work with VB. Note one important thing about VB's For-Each statement. If your container contains objects (your returned variants contain VT_UNKNOWN or VT_DISPATCH), the contained objects must implement the IDispatch interface. If they don't, you'll get an "item not an object" error at runtime from VB 6. The VB Subscript OperatorUsing the Item method, a VB client can access each individual item in the collection one at a time:
...
Dim i As Long
For i = 1 To primes.Count
sPrimes = sPrimes & primes.Item(i) & " "
Next i
...
Because I marked the Item method with DISPID_VALUE, VB allows the following abbreviated syntax that makes a collection seem like an array (if only for a second):
...
Dim i As Long
For i = 1 To primes.Count
sPrimes = sPrimes & primes(i) & " " ' Invoke(DISPID_VALUE)
Next i
...
Assigning a property the DISPID_VALUE dispatch identifier makes it the default property, as far as VB is concerned. Using this syntax results in VB getting the default propertythat is, calling Invoke with DISPID_VALUE. However, because we're dealing with array syntax in VB, we have two problems. The first is knowing where to start the index1 or 0? A majority of existing code suggests making collections 1-based, but only a slight majority. As a collection implementer, you get to choose. As a collection user, you get to guess. In general, if you anticipate a larger number of VB clients for your collection, choose 1-basedand whatever you do, please document the decision. The other concern with using array-style access is round-trips. Using the Item property puts us smack dab in the middle of what we're trying to avoid by using enumerators: one round-trip per data element. If you think that using the For-Each statement and, therefore, enumerators under VB solves both these problems, you're half right. Unfortunately, Visual Basic 6.0 continues to access elements one at a time, even though it's using IEnumVARIANT::Next and is perfectly capable of providing a larger buffer. However, using the ForEach syntax does allow you to disregard whether the Item method is 1-based or 0-based. The Server Side of EnumerationBecause the semantics of enumeration interfaces are loose, you are free to implement them however you like. The data can be pulled from an array, a file, a database result set, or wherever it is stored. Even better, you might want to calculate the data on demand, saving yourself calculations and storage for elements in which the client isn't interested. Either way, if you're doing it by hand, you have some COM grunge code to write. Or, if you like, ATL is there to help write that grunge code. |
|